
[ad_1]
Convert characters in images to text dataOptical character recognition (OCR)Widely used as a method of scanning printed documents such as invoices, receipts, and business cards. Open source OCR systems “” have achieved this type of OCR with a deep learning framework.pp-ocrv2There is a demo version of “”paddleocr“East.
PaddleOCR – A Hugging Face Space by Akhleeq
https://huggingface.co/spaces/akhaliq/PaddleOCR
GitHub – PaddlePaddle / PaddleOCR: superb multi-lingual OCR toolkit based on PaddlePaddle (ultra-light convenient OCR system, supports over 80 language recognitions, provides data annotation and synthesis tools, cross-device training server, mobile, embedded and IoT and supports deployment
https://github.com/PaddlePaddle/PaddleOCR#PP-OCRv2
Paddle OCR and PP-OCR v2 are deep learning frameworks developed by Baidu.paddle paddlebuilt on the basis of PP-OCRv2, developed by technical researcher Yuning Du and others, recognizes 80 languages, including Chinese, English and Japanese, from deep learning and generates them as text. It is said to be developed in open source with efficiency and speed.

Paddle OCR, which is a demo version of PP-OCR v2, has been released, so I’ll use it. First, Paddle OCRfirst pageuse.
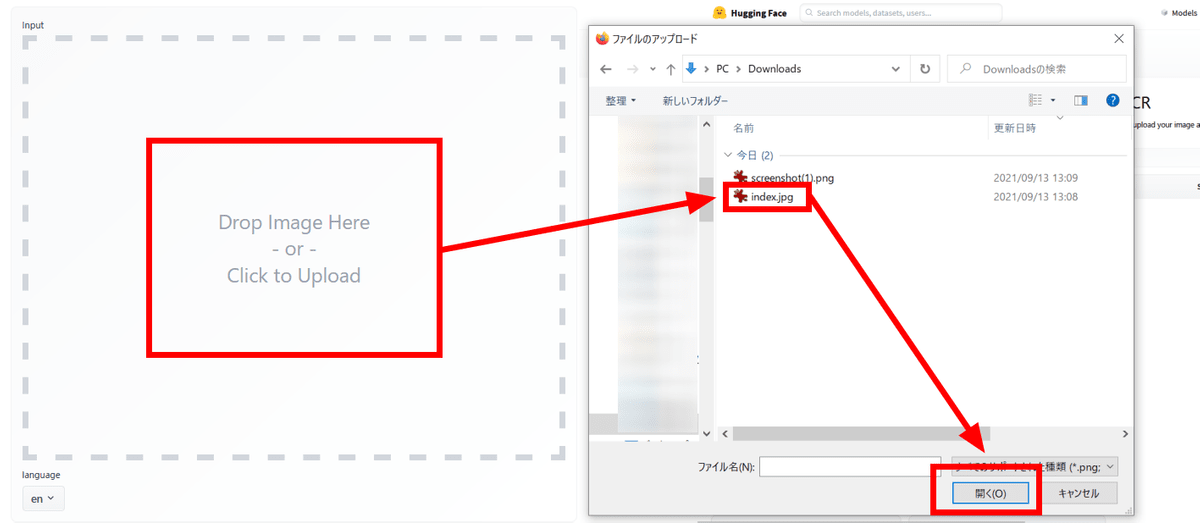
Click “Drop Image Here or Click to Download” on the left side of the screen to open Explorer. Select the image you want to OCR and upload it.
Once the download is complete, select the language you want to analyze in “Language†and click “Submitâ€. This time I will analyze it in Japanese.

After a while, the scan is complete and the result is displayed as an image file on the right side of the screen. The scan took 78.69 seconds. The scan result is output as an image file, so you cannot copy the text.
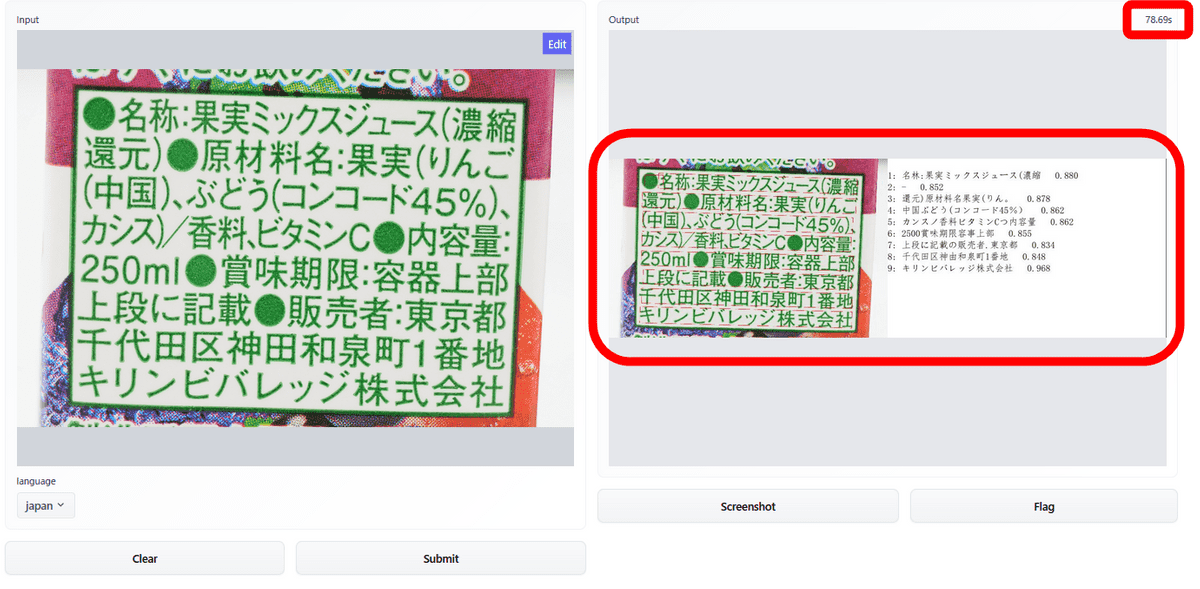
Looking at the results of the analysis in detail, it seems so. The textual information read from each paragraph and its accuracy is indicated by numbers. I have read words like “mixed fruit juice” and “raw material name”, but I can see the roughness with little precision, like “/” being “no” and “ml” being “0”.

Next comes the PS5 controller “double feelingI will try it with the package.

When I analyzed this with Japanese settings, I found that “PlayStation” reads “PIqy5LatI0n” and “Wireless Controller” reads “WIrelesSContr0ler”. It took 1.91 seconds.

When I changed the parsing language to English and parsed it again, it read with fairly high accuracy, so it’s good to change the language setting when reading the alphabet.

PaddleOCR can read in English with fairly high accuracy, but it seems that the accuracy in Japanese is not as good as in a demo version. I started using it thinking that it could be used to “read the contents of a package of a product written in a foreign language that I am not familiar with”, but since it does not come out as of text, so I can’t use this. , this is only a demo version which I was familiar with.
In addition, GitHub, Paddle OCR. Feathertoolboxis delivered.
Copy the title and URL of this article
[ad_2]